Fast Encoding Using Pre-serialization
Protocol Buffers is a popular serialization mechanism with implementations available for most major languages that allows to easily model complex data structures and has good performance characteristics. However, for performance critical applications one always wishes for faster encoding and decoding, especially when the application performs minimal processing and serialization dominates the performance profile. This post shows how it is possible to increase encoding and decoding speed several times for certain special cases.
Most of the code I write these days is in Go. There is an official Protocol Buffers implementation for Go and there is somewhat less known but often faster Gogo Proto implementation. Both libraries provide a Marshal() function to encode messages. The function traverses the in-memory representation of the messages and writes out bytes according to wire format specification. There is also a corresponding Unmarshal() function for decoding process, which does the reverse and creates the in-memory representation from the wire bytes. Marshaling and unmarshaling normally happen every time the data crosses the boundary between the wire and the process that needs to work with that data.
As I worked on Protocol Buffers schema for OpenTelemetry, I spent significant time making encoding and decoding processes faster for OpenTelemetry use cases. One way towards this goal was to come up with the right schema for messages. The same logical data can be represented in many different ways and the representation plays a big role in how fast the data can be processed. I submitted and merged dozens of PRs to modify the schema and improve performance. However as I was benchmarking and refining the schema it occurred to me there was another, orthogonal way to gain more speed.
Here I need to digress for a moment to explain how OpenTelemetry uses Protocol Buffers. Among other things OpenTelemetry SDK allows applications to publish metrics (the simplest way to think of a metric is that it is anything that can be measured as a number and that describes some aspect of a running application). Applications can have many metrics - hundreds or thousands - which are published periodically (e.g. once every few seconds). This published data then can be encoded in Protocol Buffers format and sent over the network. The data that is encoded contains information about the current values of metrics as it would be expected but it also includes additional information that describes the metrics (e.g. the name of the metric, what type is it - integer or floating-point, etc). This additional information is typically static and does not change during the lifetime of the application, only the current measured value changes. As a result a fairly complex Protocol Buffer message is encoded every time the value of a metric is published, but most of the encoded information remains the same, so the encoder does almost the same work over and over again.
Here is for example what the in-memory data structure for Metric can look like:
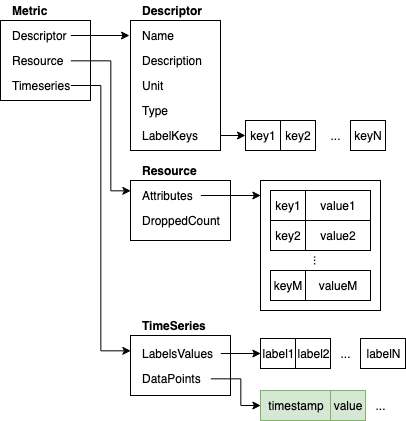
If our use case requires the program to repeatedly encode Metric messages but only a small portion of the encoded Metric actually changes then we are performing the same or very similar work repeatedly. Of the data structure shown above only data points in the TimeSeries change. The rest never changes. Encoding parts that don’t change is a waste of processing resources. So, is there a way that we can avoid this? Turns out there is.
When the Metric is encoded into a sequence of bytes the bytes that represent Descriptor and Resource never change. Here is how the serialized Metric message looks like as a sequence of bytes (for simplicity this image does not show the details inside Descriptor, Resource and TimeSeries):

It is 3 fields, each started by a key (Protocol Buffer encodes field number and type in the key) followed by the value of the serialized field.
If we could somehow encode once and keep Descriptor and Resource byte representations and reuse them on subsequent serializations we could save processing time. Looking at the Protocol Buffer Go docs there does not seem to be a way to do this directly and we seem to be out of luck. However, there is an interesting property of Protocol Buffer encoding. Reading the “Embedded Messages” sections gives us the hint:
Embedded messages are treated in exactly the same way as strings (wire type = 2).
This is not immediately clear, but what it actually means is that any embedded message (e.g. Resource embedded in Metric) is encoded on the wire such that the embedded message can be encoded first and then encoded in the containing message as if it was a just a string (or a byte array, which is the same wire type = 2).
Because of how embedded messages are encoded it does not matter whether the byte sequence representing Metric is created using a single Protocol Buffers Marshal() call or whether Descriptor was serialized separately using Marshal() and then resulting bytes sequence for Descriptor was inserted at the right place of the entire byte sequence of Metric.
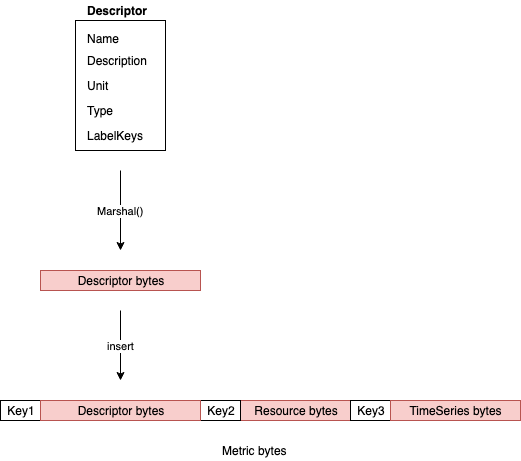
But how can we perform this “insertion”? Luckily there is an easy way, we will make Protocol Buffers encoder do it for us. We will simply declare another message type that contains the same number of fields as Metric but will declare some of them as bytes type. When encoding a message like that the Protocol Buffers encoder will simply insert those bytes at the right position. Basically we need a companion message that is wire-level compatible with our Metric message. Here is what Metric message normally looks like:
| |
If we want to be able to insert our own sequence of bytes instead of metric_descriptor and resource field here is how we can declare the companion message:
| |
We have the same 3 fields, numbered the same way, but metric_descriptor and resource are declared as bytes in MetricDescriptor. This allows us to encode MetricDescriptor and Resource messages in advance and use pre-encoded byte arrays to create MetricPrepared message. Here is an example Go code:
| |
metricBytes created this way is fully compatible on the wire with Metric message, it is indistinguishable from a byte sequence that is created from direct encoding of a Metric message with the same content. See full example code here.
Now that we have separated serialization of embedded messages from serialization of the entire Metric message we are able to serialize only once the parts that don’t change. Depending on the message complexity this can result in significant time savings. Here is the benchmark that compares full and partial serialization for this particular Metric example:
| |
BenchmarkMetricEncode/Full shows how long it takes to encode a Metric message. BenchmarkMetricEncode/Prepared shows how long it takes to encode a MetricPrepared message provided that descriptor and resource bytes are prepared in advance as it is shown in our Go example above. The benchmark shows that prepared version is about 2.2 times faster than full version.
Partial and On-demand Decoding
Another interesting way to use partial companion messages is partial decoding. Let’s imagine a use case when you need to decode a message but will only need access to certain fields and not to the others. In this case you can decode the bytes into a partial message that has only the necessary fields fully specified in the schema and the rest defined as bytes exactly the same way as we did for encoding case above.
For example we could receive on the wire a fully encoded Metric but decide to decode it into a MetricPrepared message. In that case we will have direct access to Int64Timeseries, however the rest of the fields will remain in wire format.
| |
Below is the benchmark that compares decoding of the same wire data into Metric and partial decoding into MetricPrepared:
| |
The partial decoding in our example is almost 3x faster than full decoding.
Another very nice property of this approach is that should we later at some point in our code need access to those non-decoded fields we can call proto.Unmarshal() on the byte array content of those fields and we will get fully decoded fields. This allows implementing all sorts of interesting high-performance pass-through scenarios with partial decoding or lazy decoding of certain fields on-demand. Here is an example:
| |
Final Words
Defining companion message schemas based on Protocol Buffers encoding is an interesting way to get more performance in certain specialized scenarios where we don’t need access to all fields in the message all the time.
It is also possible to simultaneously have multiple companion message definitions for a single message wire format and use the definition that is required in a particular use case. Simply define fields that are necessary at run time and leave the rest as bytes fields in message schema.